第1章 第4节 文字接龙(一)-游戏
第1章 第4节 文字接龙(一)-游戏
Tip
阅读指南
在上一节,我试图让你理解ChatGPT本质上是一个函数——一个有1750亿个参数的、从海量数据中训练出来的函数。但这只是形式上的理解。现在,让我们进入更核心的问题:这个函数到底在计算什么?
当你打开ChatGPT的对话框,输入一个问题,按下回车键,在那短短几秒钟内,这个有着1750亿参数的庞然大物,究竟在做什么?
答案简单到令人惊讶,简单到我第一次听说时都有些不敢相信:它在不断地预测下一个词。
仅此而已。
Caution
注意,本章第1节我们讨论的是参数的具体值是怎么"训练"出来的;而这一节我们讨论的是,参数训练好后,她是怎么工作的?这个思维一定要转变一下。
4.1 文字接龙
贪吃蛇游戏
让我先带你回到童年。你一定玩过"贪吃蛇"这个游戏吧? 吃之前:
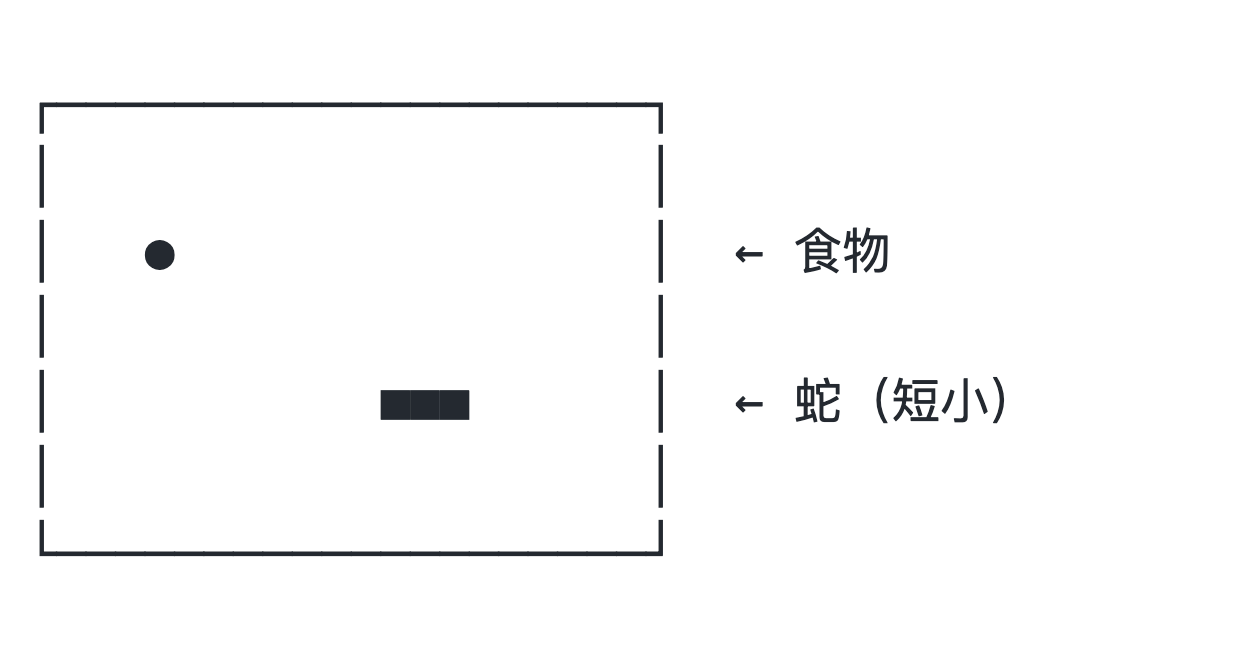
吃之后:
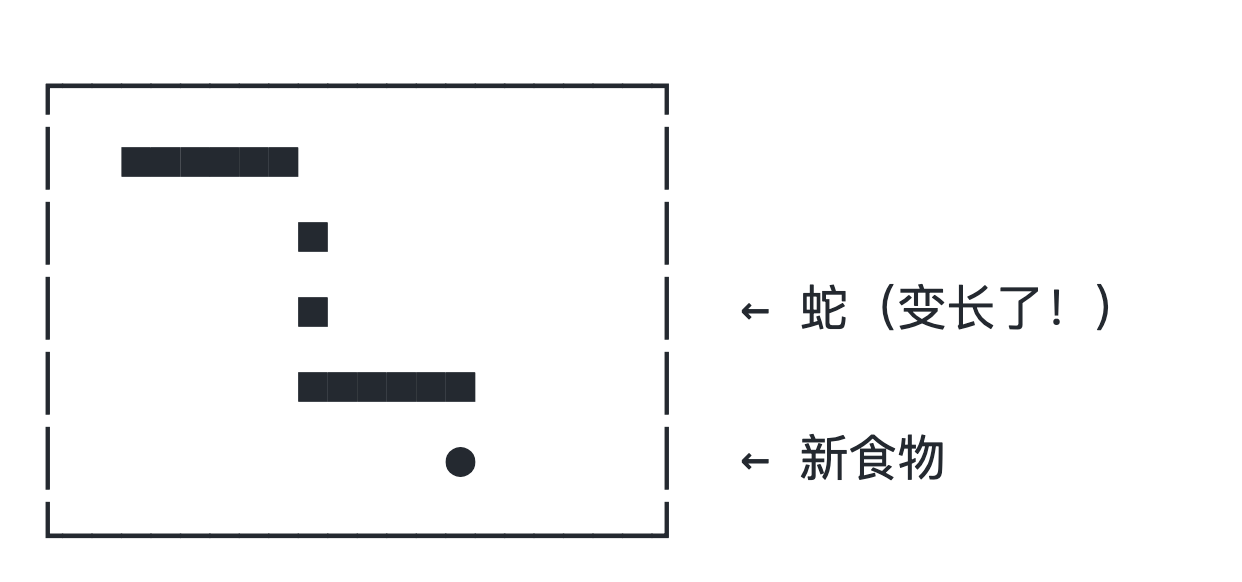
这个游戏的规则极其简单:每次吃到食物,食物就变成蛇身的一部分,蛇身不断变长。就这样一个接一个,蛇越来越长。
ChatGPT在做的事情,本质上也是贪吃蛇游戏。
但与贪吃蛇不同,ChatGPT玩的是文字版的贪吃蛇——每预测出一个新词("吃到食物"),就把它加到已生成的文本中("变成蛇身的一部分"),然后继续预测下一个词。就像这样:
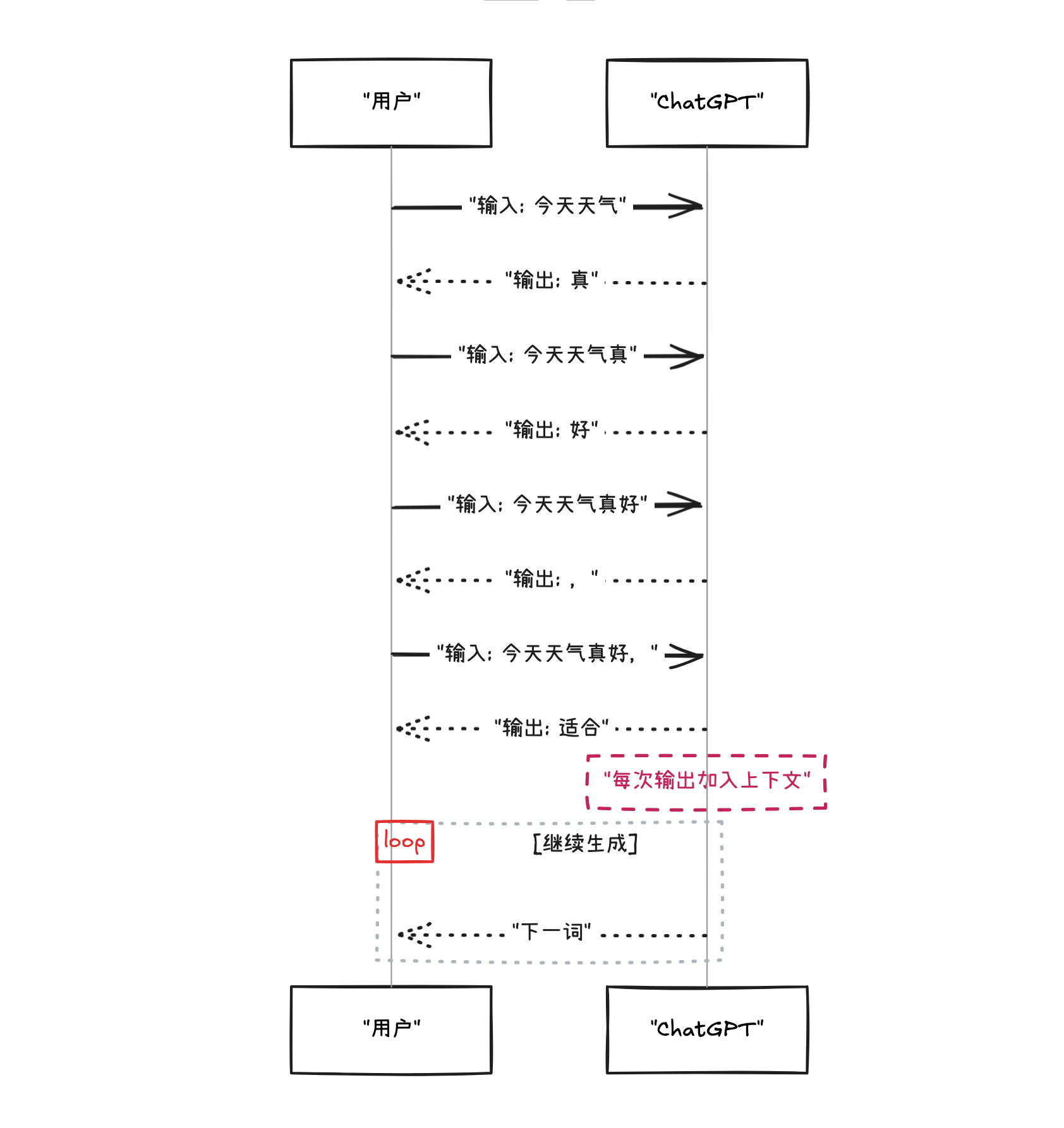
所以,ChatGPT并不是一次将答案全部生成好,而是不断的预测下一个词,最终形成一个完整的答案,并回复给你。
这个机制叫做自回归,我们会在后面详细讲解。
4.2 一个实际的例子:看看它是怎么"接龙"的
让我给你演示一个具体的过程,让你看看ChatGPT内部到底在发生什么。
假设你问它:"今天上海的天气怎么样?"
在你看来,这只是一个简单的问题。但在ChatGPT内部,一场复杂的概率计算已经开始了。
ChatGPT会先"看"你的问题,然后开始一个词一个词地预测答案。
- 第一步:计算第一个回答词的概率
在"今天上海的天气怎么样?"这个问题之后,第一个回答词是什么?
ChatGPT有一个自己的"词表"。她会扫描这个词表,为每一个词计算一个概率。
| 候选词 | 概率 | 备注 |
|---|---|---|
| 今天 | 25% | 最可能 |
| 上海 | 20% | |
| 目前 | 15% | |
| 现在 | 12% | |
| 根据 | 10% | |
| 天气 | 8% | |
| ... | ... | 其他数万个token的概率都很低,接近0 |
这个概率分布,就是数千亿个参数共同计算出来的结果。每个参数都在这个计算中发挥作用,最终汇聚成这个概率列表。
Note
GPT系列词表大小:
- GPT-2/GPT-3: 50,257 词
- GPT-3.5/GPT-4: 100,256 词
- GPT-4o: 200,064 词
- 第二步:选择一个词
ChatGPT根据这个概率分布,选择了"今天"这个词(最可能的那个)。现在我们有了:
问题:今天上海的天气怎么样?
回答:今天
- 第三步:重复这个过程
现在,ChatGPT再次计算。注意,这次的上下文变了,它看到的是:
问题:今天上海的天气怎么样?
已生成:今天
在这个新的上下文之后,下一个词的概率分布:
| 候选词 | 概率 | 备注 |
|---|---|---|
| 上海 | 40% | 压倒性优势 |
| 的 | 25% | |
| 天气 | 18% | |
| 相当 | 10% | |
| 比较 | 5% | |
| ... | ... |
选择"上海",得到:
问题:今天上海的天气怎么样?
回答:今天上海
- 第四步:继续接下去
再次计算概率:
| 候选词 | 概率 |
|---|---|
| 的 | 45% |
| 天气 | 30% |
| 比较 | 12% |
| 相对 | 8% |
| ... | ... |
选择"的",得到:
问题:今天上海的天气怎么样?
回答:今天上海的
- 第五步到第N步...
就这样,一个词一个词地接下去:
今天上海的天气
今天上海的天气相当
今天上海的天气相当不错
今天上海的天气相当不错,
今天上海的天气相当不错,温度
今天上海的天气相当不错,温度在
今天上海的天气相当不错,温度在20
今天上海的天气相当不错,温度在20度
今天上海的天气相当不错,温度在20度左右
今天上海的天气相当不错,温度在20度左右,适合
今天上海的天气相当不错,温度在20度左右,适合户外
今天上海的天气相当不错,温度在20度左右,适合户外活动。
每一步,都是在根据问题+已生成的回答,计算所有可能的下一个词的概率,然后选择一个。
这就是文字接龙。一个看似简单,实则精妙的过程。
4.3 ■ 学点英语
| 中文 | English | 音标 | 说明 |
|---|---|---|---|
| 自回归 | Autoregressive | /ˌɔːtoʊrɪˈɡresɪv/ | 每次基于已生成序列预测下一个词,逐步构建完整输出的生成方式 |
| 概率分布 | Probability Distribution | /ˌprɑːbəˈbɪləti ˌdɪstrɪˈbjuːʃən/ | 模型为所有候选词计算出的概率列表,总和为1 |
| 词表 | Vocabulary | /vəˈkæbjəleri/ | 模型能识别和生成的所有词的集合 |
| 上下文 | Context | /ˈkɑːntekst/ | 模型预测下一个词时参考的已生成文本 |
| 采样 | Sampling | /ˈsæmplɪŋ/ | 根据概率分布从候选词中选择一个词的过程 |